
集算器
北京润乾信息系统技术有限公司






集算器作为创新的数据计算引擎,有效地提高了复杂结构化大数据计算的开发速度和运算效率。弥补了关系型数据库与Hadoop之间的空白,完美解决了跨数据源、多数据源的混合计算问题,为客户提供了弹性的计算框架,有效地为客户提供了个性化数据服务。
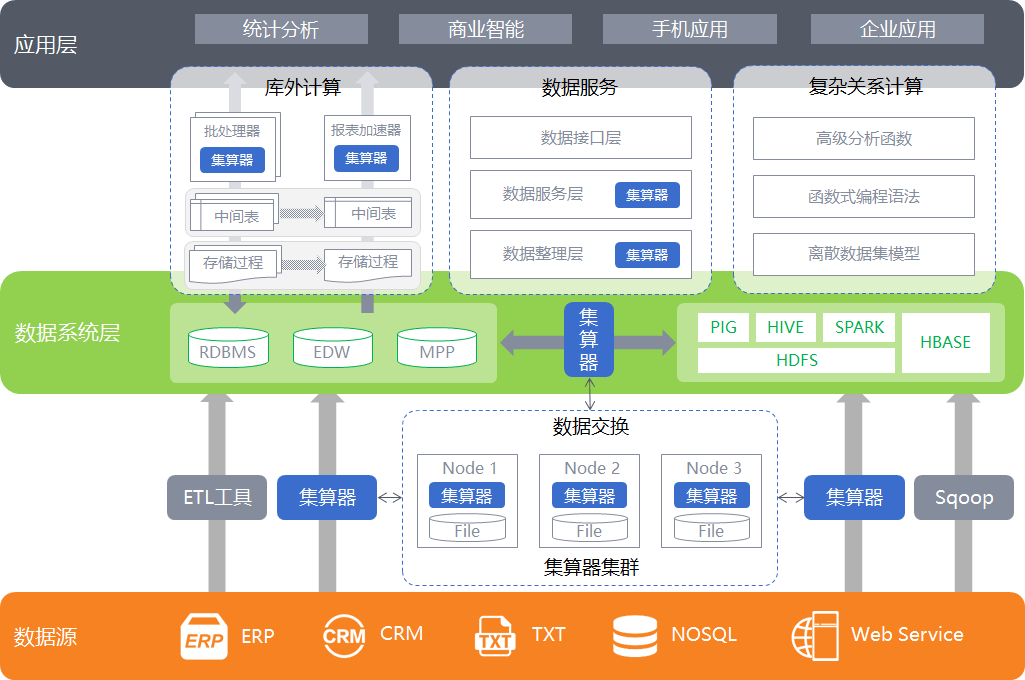
对于报表业务,除个别涉及数据量巨大,库内计算效率会更高,应当尽量少用存储过程,做算法外置,降低和数据库的耦合;库内计算资源是有限的,对于批处理过程,提前将数据外置,集算器可以替代数据库完成相同计算任务,节省库内计算资源,减少中间表的产生,为数据库瘦身。
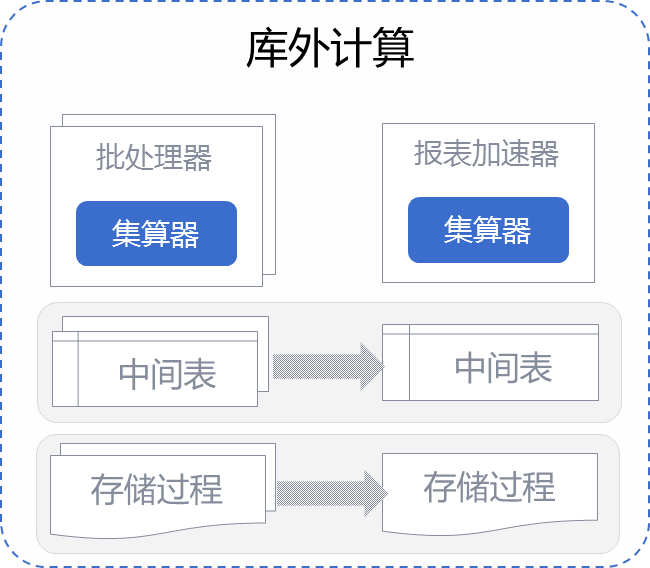
数据中心对外提供的数据,经常来自多个异构数据源,使用SQL和存储过程没法跨库计算,利用集算器跨库计算能力,将数据事先清洗、脱敏、计算整理好,为数据接口层提供数据服务。

SQL集合化很好,离散性不好,复杂计算用SQL很难写,集算器离散数据集模型是集合化和离散性的统一,更彻底的集合化;支持分组子集、有序聚合、逆分组;强化有序计算,实现跨行引用、有序分组、位置利用;多级游标、程序游标、有序游标解决大数据量下的分析计算。
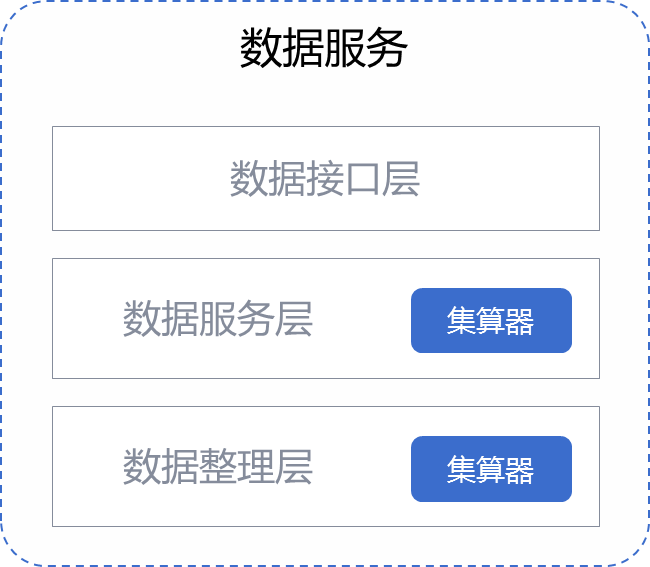
使用集算器可将txt,csv,xlsx,nosql,json,xml等多样数据源先计算后入库;将数据抽取到分析库中再做计算,浪费宝贵的计算资源,也不是数仓的本职工作,使用集算器将分散的、异构数据源中的数据抽取到临时中间文件后进行清洗、转换、集成,最后加载到数据仓库。
更多产品介绍见:http://www.raqsoft.com.cn/p